Изображение с сайта (https://pythonru.com/baza-znanij/metriki-accuracy-precision-i-recall)
1. Определения (бинарная классификация)
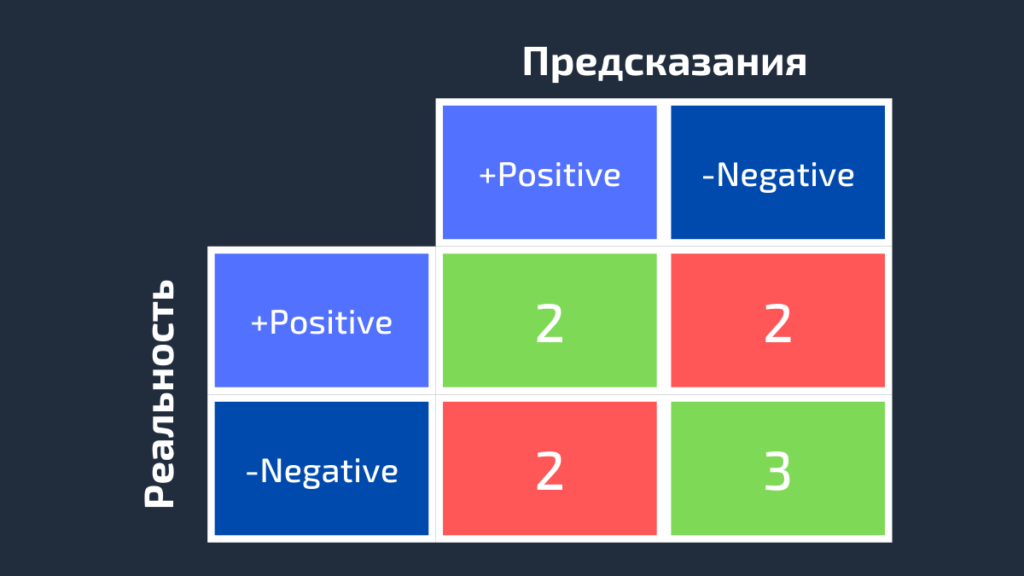
Матрица ошибок (Confusion Matrix) — основа всех метрик
Это таблица, которая визуализирует производительность алгоритма классификации, сравнивая фактические метки (Actual) с предсказанными (Predicted).
Структура для бинарной классификации (классы 1 и 0):
| Predicted: 1 (Положительный) | Predicted: 0 (Отрицательный) | |
|---|---|---|
| Actual: 1 (Положительный) | TP (True Positive) | FN (False Negative) |
| Actual: 0 (Отрицательный) | FP (False Positive) | TN (True Negative) |
Подробное определение каждого элемента:
-
True Positive (TP, Истинно положительный)
- Факт: Объект принадлежит классу 1.
- Предсказание: Модель предсказала класс 1.
- Результат: Успех! Модель правильно нашла целевой объект.
- Пример: Больной человек, которому правильно поставили диагноз.
-
True Negative (TN, Истинно отрицательный)
- Факт: Объект принадлежит классу 0.
- Предсказание: Модель предсказала класс 0.
- Результат: Успех! Модель правильно отвергла объект, не принадлежащий целевому классу.
- Пример: Здоровый человек, которого правильно признали здоровым.
-
False Positive (FP, Ложно положительный) — Ошибка I рода
- Факт: Объект принадлежит классу 0.
- Предсказание: Модель предсказала класс 1.
- Результат: Ошибка! Ложное срабатывание, "ложная тревога". Модель приняла "шум" за сигнал.
- Пример: Здорового человека ошибочно объявили больным. Спам-фильтр отправил важное письмо в спам.
-
False Negative (FN, Ложно отрицательный) — Ошибка II рода
- Факт: Объект принадлежит классу 1.
- Предсказание: Модель предсказала класс 0.
- Результат: Ошибка! Пропуск цели. Модель не смогла обнаружить целевой объект.
- Пример: Больному человеку не поставили диагноз. Мошенническая транзакция не была обнаружена.
Как связаны метрики и матрица ошибок?
Все основные метрики выводятся непосредственно из четырех чисел матрицы (TP, TN, FP, FN):
-
Accuracy = (TP + TN) / (TP + TN + FP + FN)
-
Accuracy (Точность): Доля правильно предсказанных объектов среди всех объектов.
Accuracy = (TP + TN) / (TP + TN + FP + FN)
-
Precision (Точность/Прецизионность): Доля истинно положительных объектов среди всех объектов, которые модель предсказала как положительные. "Насколько мы можем доверять, что предсказанный класс 1 — это действительно класс 1?"
Precision = TP / (TP + FP)
-
Recall (Полнота): Доля правильно предсказанных положительных объектов среди всех реально положительных объектов. "Какую долю всех интересующих нас объектов мы смогли найти?"
Recall = TP / (TP + FN)
-
F1-score (F-мера): Гармоническое среднее между Precision и Recall. Одна метрика, балансирующая оба аспекта.
F1 = 2 * (Precision * Recall) / (Precision + Recall)
-
ROC AUC (Area Under the ROC Curve): Площадь под кривой ROC (Receiver Operating Characteristic). Кривая ROC показывает зависимость True Positive Rate (Recall) от False Positive Rate (FPR = FP/(FP+TN)) при изменении порога классификации. AUC показывает способность модели ранжировать объекты (вероятность того, что случайный "положительный" объект будет иметь оценку выше, чем случайный "отрицательный"). AUC не зависит от порога.
2. Почему F1 — гармоническое среднее?
Гармоническое среднее сильнее "наказывает" за экстремальные значения, чем среднее арифметическое. Если одна из метрик (Precision или Recall) близка к нулю, F1 также будет близок к нулю, даже если вторая метрика высока.
- Пример: Precision = 1.0, Recall = 0.01.
- Среднее арифметическое:
(1.0 + 0.01)/2 = 0.505— выглядит приемлемо. - Гармоническое среднее (F1):
2*(1*0.01)/(1+0.01) ≈ 0.02— отражает катастрофически низкое качество.
- Среднее арифметическое:
Это делает F1 строгой и консервативной метрикой, которая требует сбалансированности между Precision и Recall, что критично во многих практических задачах.
3. В каких задачах важны precision и recall?
Выбор приоритетной метрики зависит от стоимости ошибок:
-
Важен высокий Precision (минимизация FP):
- Спам-фильтр: Ложное срабатывание (FP) — важное письмо попало в спам (высокая цена ошибки). Пропустить спам (FN) — менее критично.
- Диагностика тяжелой болезни (когда лечение рискованно): FP — здоровому человеку поставили опасный диагноз и начали тяжелое лечение. Лучше пропустить несколько случаев (FN), чем навредить здоровым.
- Рекомендательные системы (показ товара): FP — показать пользователю нерелевантный товар (потеря доверия, клика). FN — не показать товар, который ему бы подошел.
-
Важен высокий Recall (минимизация FN):
- Диагностика тяжелой болезни (когда лечение простое): FN — не выявить болезнь у больного (катастрофа). FP — направить здорового на дополнительные анализы (меньшая цена).
- Поиск мошеннических операций: FN — пропустить мошенничество (прямые убытки). FP — заблокировать легитимную транзакцию (неудобство для клиента).
- Поиск информации (Search): Захватить все релевантные документы.
4. Как управлять precision/recall через порог?
Модели часто предсказывают вероятность принадлежности к классу 1. Порог — это число, выше которого мы относим объект к классу 1.
-
Повышение порога (становимся строже, чтобы предсказать "1"):
- Precision, скорее всего, вырастет: мы выдаем "1" только для самых уверенных случаев → среди них меньше ложных (FP).
- Recall, скорее всего, упадет: мы начинаем пропускать много объектов, которые на самом деле "1", но с вероятностью чуть ниже порога (FN растет).
-
Понижение порога (становимся мягче):
- Recall, скорее всего, вырастет: мы "ловим" больше реальных "1".
- Precision, скорее всего, упадет: среди предсказанных "1" появляется много ложных (FP).
Таким образом, двигая порог, мы двигаемся по кривой Precision-Recall и можем выбрать операционную точку, оптимальную для конкретной задачи.
5. Почему accuracy — плохая метрика?
Accuracy хороша только при сбалансированных классах. При дисбалансе она вводит в заблуждение.
- Классический пример: Дисбаланс 95:5 (95% класса 0, 5% класса 1).
- Модель-константа, всегда предсказывающая класс 0, получит
Accuracy = 0.95. Отличный результат? Нет, она вообще не находит целевой (миноритарный) класс (Recall = 0).
- Модель-константа, всегда предсказывающая класс 0, получит
- Accuracy не дифференцирует типы ошибок (FP и FN), стоимость которых может быть радикально разной.
6. Как оценивать качество модели?
- Определить бизнес-цель и стоимость ошибок (что важнее: Precision или Recall?).
- Выбрать основную метрику (F1, ROC AUC, Precision@K, средняя точность и т.д.), соответствующую цели.
- Смотреть не на одну метрику, а на комплекс:
- Матрица ошибок (Confusion Matrix) — основа для понимания.
- Precision, Recall, F1 — для бинарной и мультиклассовой.
- ROC-кривая и AUC — для оценки качества ранжирования (независимо от порога).
- PR-кривая (Precision-Recall) — особенно полезна при сильном дисбалансе классов, так как фокусируется на классе 1, игнорируя TN.
- Валидация: Использовать кросс-валидацию для устойчивой оценки.
- Подбор порога: После фиксации модели выбрать порог на валидационной выборке, оптимизируя под нужный баланс Precision/Recall.
7. Как ведут себя метрики при дисбалансе?
- Accuracy: Бесполезна, завышена.
- Precision: Может быть высокой даже у простой модели (если класс 1 редок, то даже небольшое количество предсказанных "1" может быть чистым).
- Recall: Часто низкая, так как модель плохо учится detect миноритарный класс.
- F1: Более адекватна, так как учитывает обе стороны.
- ROC AUC: Может оставаться обманчиво высокой из-за большого количества TN (ось FPR мало меняется). Не рекомендована при сильном дисбалансе.
- PR-AUC (Area Under PR-Curve): Предпочтительный выбор при дисбалансе. Кривая Precision-Recall фокусируется на качестве предсказания положительного класса и игнорирует TN, что делает ее чувствительной к дисбалансу.
8. Как считать метрики при многоклассовой классификации?
Есть два основных подхода: Макро-усреднение (Macro-average) и Микро-усреднение (Micro-average).
-
Macro-average: Считаем метрику (Precision, Recall, F1) для каждого класса отдельно, затем усредняем. Каждый класс вносит равный вклад, независимо от его размера. Хорош, когда все классы одинаково важны. Чувствителен к качеству по малым классам.
Precision_macro = (Precision_class1 + Precision_class2 + ... + Precision_classN) / N
-
Micro-average: Считаем глобальные TP, FP, FN, TN по всем классам (например, для класса "кошка" — все остальные классы будут "не кошка"), а затем вычисляем одну общую метрику. Взвешивает классы по их размеру (большие классы влияют сильнее). Фактически, Micro-average Precision = Micro-average Recall = Accuracy.
Precision_micro = (TP₁ + TP₂ + ... + TPₙ) / ((TP₁+TP₂+... + TPₙ) + (FP₁+FP₂+...+FPₙ))
-
Weighted-average: Вариант Macro, где усреднение идет с весами, пропорциональными поддержке (количеству объектов) каждого класса. Учитывает и важность всех классов (как macro), и их размер.
На практике: * Если классы сбалансированы и одинаково важны → Macro-F1. * Если классы несбалансированы и мы хотим учесть размер классов → Weighted-F1 (часто де-факто стандарт для отчетности). * Micro-F1 используется реже, так как в многоклассовой задаче сводится к Accuracy.
Оставить отзыв
Комментарии
Загрузка комментариев...
★ Оставить отзыв